Links
Summer at NCCR and EPFL
This work is the result of an amazing collaboration with EPFL and NCCR Automation. The project’s contributions are owed to dedicated work and ideas of senior PhD candidate, Mahrokh G. Boroujeni, and Prof. Giancarlo Ferrari-Trecate, both from EPFL’s Laboratoire d’Automatique.
Special thanks to NCCR’s Visiting Researcher’s Fellowship and EPFL’s hospitality for arranging a productive work environment throughout my stay.
Summary of the work
Imitation learning is a data-driven approach to learning policies from expert behavior, but it is prone to unreliable outcomes in out-of-sample (OOS) regions. While previous research relying on stable dynamical systems guarantees convergence to a desired state, it often overlooks transient behavior. We propose a framework for learning policies modeled by contractive dynamical systems, ensuring that all policy rollouts converge regardless of perturbations, and in turn, enable efficient OOS recovery. By leveraging recurrent equilibrium networks and coupling layers, the policy structure guarantees contractivity for any parameter choice, which facilitates unconstrained optimization. We also provide theoretical upper bounds for worst-case and expected loss to rigorously establish the reliability of our method in deployment. Empirically, we demonstrate substantial OOS performance improvements for simulated robotic manipulation and navigation tasks.
Method overview
The contraction property enables efficient out-of-sample recovery, especially in the face of perturbations. By utilizing contractive policies, we extend beyond the typical convergence guarantees of stable dynamical systems, offering certificates on the transient behavior of induced trajectories in addition to global convergence guarantees. We achieve notable improvements in out-of-sample recovery for various robots in navigation and manipulation tasks.
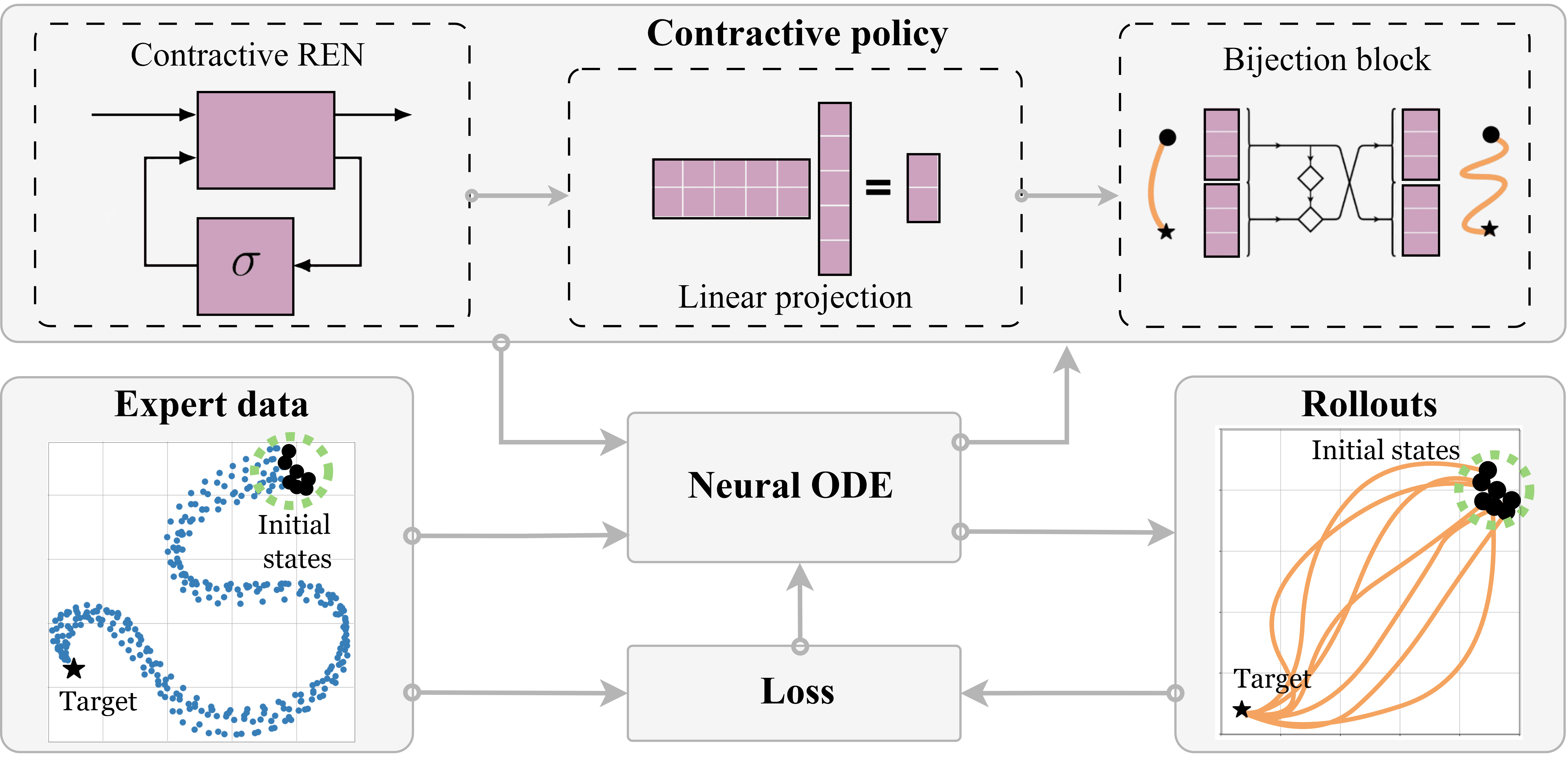
There are three main steps in learning contractive policies with SCDS:
Initial conditions are passed to the differentiable Neural ODE solver to generate state trajectories.
A tailor-made loss penalizes the discrepancy of the generate and expert trajectories, and updates the policy parameters.
Within the contractive policy, the REN module ensures contraction, the linear transformation adjusts the dimension of the latent space, and the bijection block boosts the policy’s expressive power while preserving contraction properties.
Summary of results
After training on expert demonstrations, the policy can be deployed with a low-level controller. The contractivity and, in turn, global stability of the policy facilitates reliable execution and out-of-sample recovery.
Theoretically, our method can be deployed for planning in various robotics systems and scenarios. We explore such use case for manipulation and navigation on Franka Panda and Clearpath Jackal robots, respectively.

Reviews
In case you are interested in the review process, check this page.
What is ICLR?
ICLR is the premier gathering of professionals dedicated to the advancement of the branch of artificial intelligence called representation learning. Check out their website for detailed info of ICLR in recent years!
Citation
“Contractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations.” ICLR 2026, under review.
@inproceedings{abyaneh2025contractive,
title={Contractive Dynamical Imitation Policies for Efficient Out-of-Sample Recovery},
author={Amin Abyaneh and Mahrokh Ghoddousi Boroujeni and Hsiu-Chin Lin and Giancarlo Ferrari-Trecate},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=lILEtkWOXD}
}