Links Paper Project page Slides Summer at NCCR and EPFL This work is the result of an amazing collaboration with EPFL and NCCR Automation. The project’s contributions are owed to dedicated work and ideas of senior PhD candidate, Mahrokh G. Boroujeni, and Prof. Giancarlo Ferrari-Trecate, both from EPFL’s Laboratoire d’Automatique.
Special thanks to NCCR’s Visiting Researcher’s Fellowship and EPFL’s hospitality for arranging a productive work environment throughout my stay.
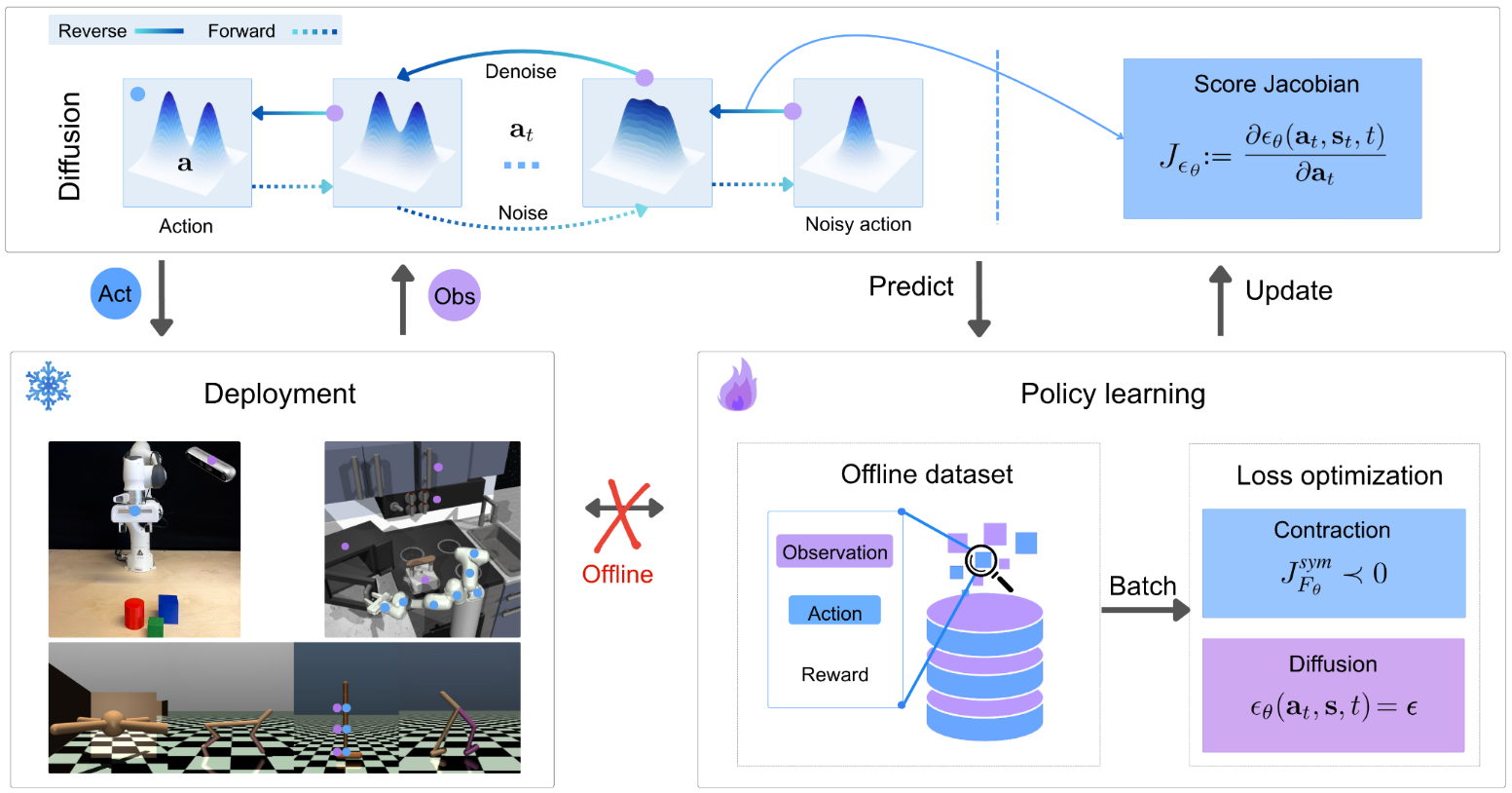
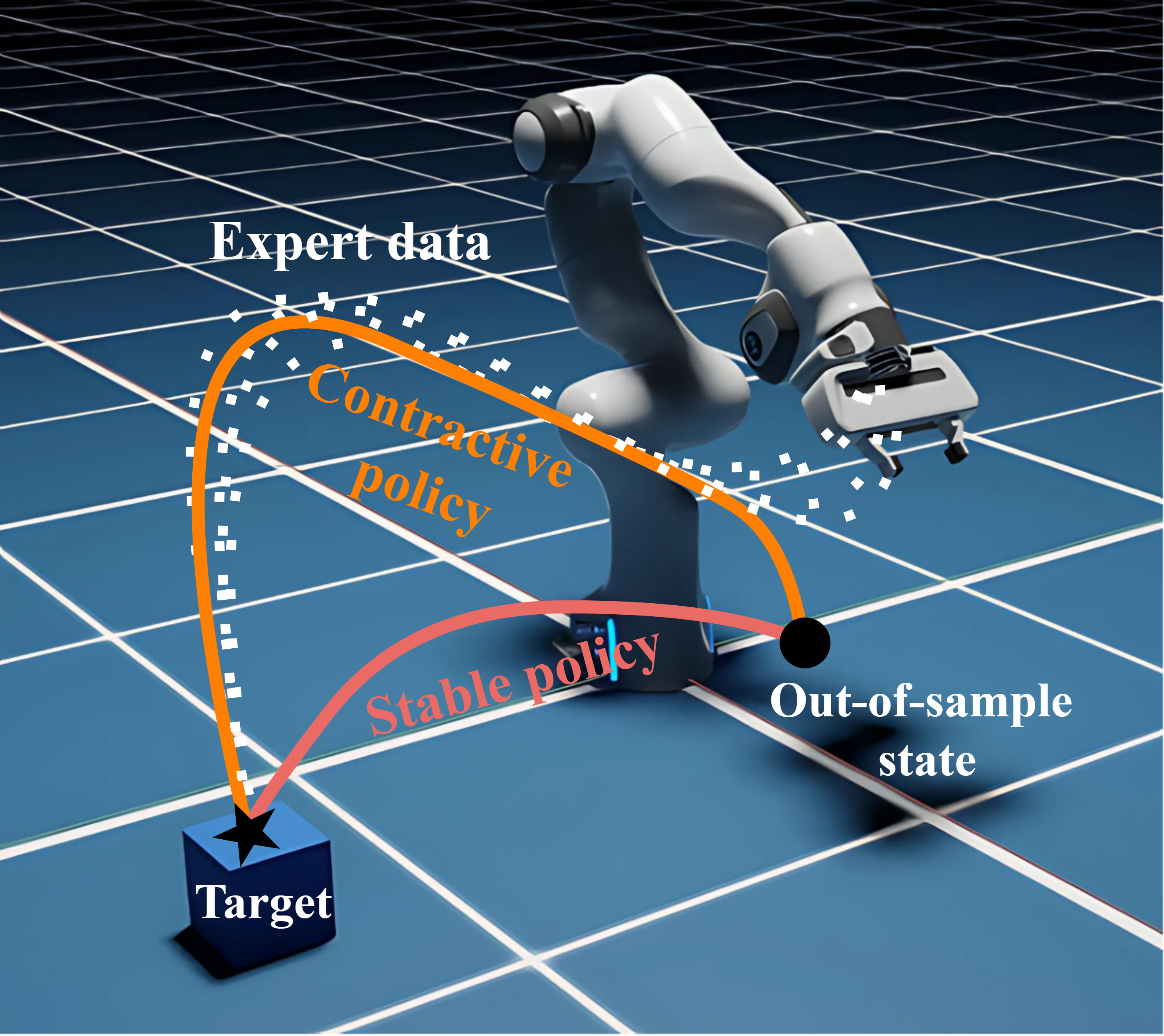
Summary of the work Imitation learning is a data-driven approach to learning policies from expert behavior, but it is prone to unreliable outcomes in out-of-sample (OOS) regions. While previous research relying on stable dynamical systems guarantees convergence to a desired state, it often overlooks transient behavior. We propose a framework for learning policies modeled by contractive dynamical systems, ensuring that all policy rollouts converge regardless of perturbations, and in turn, enable efficient OOS recovery. By leveraging recurrent equilibrium networks and coupling layers, the policy structure guarantees contractivity for any parameter choice, which facilitates unconstrained optimization. We also provide theoretical upper bounds for worst-case and expected loss to rigorously establish the reliability of our method in deployment. Empirically, we demonstrate substantial OOS performance improvements for simulated robotic manipulation and navigation tasks.
...